この記事は FOLIO Advent Calendar 2024 - Adventar の21日目です。
先日 HashedWheelTimer が話題に上がったのですが、意外にも日本語で解説している記事が見当たりませんでした。(言及している記事はある。検索の仕方が悪いかもしれない。)
HashedWheelTimer は Web フレームワークなどの裏側でタイムアウトを扱ったり、スケジューリング周りで重要なデータ構造/アルゴリズムです。 理解しておくとトラブル時に役立つ(かも)ということで自分の勉強も兼ねてまとめておきます。
HashedWheelTimer とは
何 millisec 後にタイムアウトしてほしい、何秒周期でタスクをリピートしてほしいといった際に Timer や Scheduler のような名前のクラスを利用することがあると思います。 HashedWheelTimer はそのような Timer or Scheduler 実装の一つで特に大量のタイマーイベントを効率的に管理することが可能なデータ構造です。
例えば HTTP フレームワークの裏側で netty の HashedWheelTimer クラスが大量のリクエストタイムアウトを扱っているといったことがあります。(他にも retry 処理で N 秒後に実行したいといったユースケースなども考えられます。)
今回は nettyの HashedWheelTimer クラスのコメント に論文とスライドへのリンクがあるのでこれをベースに解説しようと思います。
資料
前提: 1987年の論文です。
- Varghese, G., and Lauck, A. (1987). “Hashed and hierarchical timing wheels: data structures for the efficient implementation of a timer facility,” in Proceedings of the eleventh ACM symposium on operating systems principles, 25–38.
- Hashed and Hierarchical Timing Wheels (ppt)
なお論文タイトルではHashed Timing Wheelとなっていますが、これを使ったTimer実装がHashed Wheel Timerだと思えば大丈夫です。論文にのっていたので亜種である Hierarchical Timing Wheels についても解説します。
Hashed and hierarchical timing wheels: data structures for the efficient implementation of a timer facility の説明
扱う課題
以下の操作を持つタイマーを考えます。
START_TIMER(interval, request_id, expiry_action): 指定時刻が経過したら expiry_action を実行(例: 503 HTTPレスポンスを送出、TCPパケットを再送)STOP_TIMER(request_id): タイマーのキャンセルPER_TICK_BLOOKKEEPING: 毎tick行う処理EXPIRY_PROCESSING: expiry_actionの対象の選択と実行
これらの操作をメモリー効率・レイテンシ(各操作にかかる時間)を指標として改善するのが課題となります。レイテンシについては平均ケース・最悪ケースの両方を見る必要があります。
特に timer の時間解像度が高い(= tick 間隔が短い)場合や、tick ごとにたくさんの expiry_action を実行しなければならない場合は PER_TICK_BLOOKKEEPING や EXPIRY_PROCESSING の性能が重要となります。もちろんたくさんの expiry_action があるということはそれだけたくさん START_TIMER が呼ばれているということでもあるので、こちらの性能も重要となります。
すごくシンプルに実装するとタイマーの開始や管理に O(n)の時間がかかってしまいます。今回の論文では複数のタイマーアルゴリズムについて検討・比較し、さらに拡張として Hashed Timing Wheel と Hierarchical Timing Wheel という2つの手法を解説しています。
今までのタイマー実装
ここから先は資料2のスライドの図を見ながら読むとイメージがつきやすくなると思います。
方式1 - 単純な実装
- 仕組み
- 空き領域を見つけて、そこにタイマーレコードを格納する(書いてないですがおそらく配列のようなもの?)
- tickごとに呼び出される PER_TICK_BOOKKEEPING ではタイマーを1減らし、0になったら EXPIRY_PROCESSING を呼び出す
- パフォーマンス特性
- PER_TICK_BOOKKEEPING 以外は O(1)。 PER_TICK_BOOKKEEPING は O(n)
- タイマーが少数の場合(すぐ expire する場合も含む)は有効な手法
方式2 - 順序付きリスト/タイマーキュー
- 仕組み
- タイマーを絶対時刻で期限切れになる順にソートした順序付きリスト(論文の figure 2 では双方向連結リスト)に格納する(リストの先頭が一番早く期限切れになる)
- PER_TICK_BOOKKEEPING について
- 現在時刻を増やして、リストの先頭と比較するだけでOK(期限切れだったら EXPIRY_PROCESSING を呼んで次の要素も見に行く)
- START_TIMER について
- 新しいタイマーの挿入位置を検索する必要があるので最悪ケースでは O(n) かかる。
- 平均ケースはタイマー間隔とタイマー到着の分布に依存する。(おおむね O(n) になる。)
- STOP_TIMER について
- 他の方式でも使えるが START_TIMER 時に挿入した要素へのポインタを返すことで STOP_TIMER は O(1) で動作させることが出来る
- 双方向連結リストなので要素の削除は O(1)
- パフォーマンス特性
方式2 ではタイマーリストをソートすることで PER_TICK_BOOKKEEPING のレイテンシーを削減しましたが、代わりに START_TIMER のコストが増加してしまいました。 方式1 では START_TIMER が速く、PER_TICK_BOOKKEEPING が遅かったのでちょうど反対の関係になります。
この論文はこの二つの操作を早くしたいというのがモチベーションになっています。(STOP_TIMERもありますが、これは比較的簡単に早くできるのであまり気にしない)
改善の発想源になるのはソートアルゴリズムと離散時間シミュレーションです。本ブログではソートアルゴリズムの方との比較についてのみ記載します。シミュレーションの方が気になる人は論文をご覧ください。
タイマーアルゴリズムとソートアルゴリズム
ここでタイマーモジュールとソートアルゴリズムの関係を見てみると
- 通常のソートでは全要素が最初に入力され最後にソート済みで出力される。一方でタイマーモジュールでは要素が異なる時点で何度も到着し何度もソートする必要がある
- タイマーモジュールでは間隔を保存する場合ソート対象の要素が時間とともに値が変化する。(絶対時間で保存する場合は発生しない問題)
という違いがあることがわかります。
こういった場合に使えるデータ構造にプライオリティキューがあります。
プライオリティキューでは - 要素の挿入と削除が可能 - 集合内の最小要素を取得可能 (キューの先頭を常に最小要素 = 最初に expire する要素にできる)
プライオリティキューベースでの実装では PER_TICK_BOOKKEEPING を O(1) で実行することが出来ます。これを前提に START_TIMER を方式2 = O(n) から改善できるか考えてみましょう。
方式3. - ツリーベースのアルゴリズム
実はLinkedListベースの方式2もプライオリティキューの一実装ですが、大きなnに対してはツリーベースのデータ構造が優れています。 これを使うと START_TIMER を O(n) から O(log(n)) に削減することが出来ます。
非平衡二分木を使うと性能が良いようですが、バランス操作を伴わないため線形リストと同じ形になってしまう可能性があります。(常に右側にしか子要素がない非平衡二分木は線形リストと同じ)
PER_TICK_BOOKKEEPING が O(1) 、START_TIMER が O(log(n)) に削減できました。更に考えを進めていきましょう。
方式4. タイミングホイール方式
デジタルシミュレーションで使われている方式をタイマー用に修正した方式です。(論文には元のアルゴリズムの記載がありますがカット)
すべてのタイマーがMaxInterval未満の期間に設定される場合、このアルゴリズムでは以下の処理が O(1) で実行可能です。
- START_TIMER
- STOP_TIMER
- PER_TICK_BOOKKEEPING
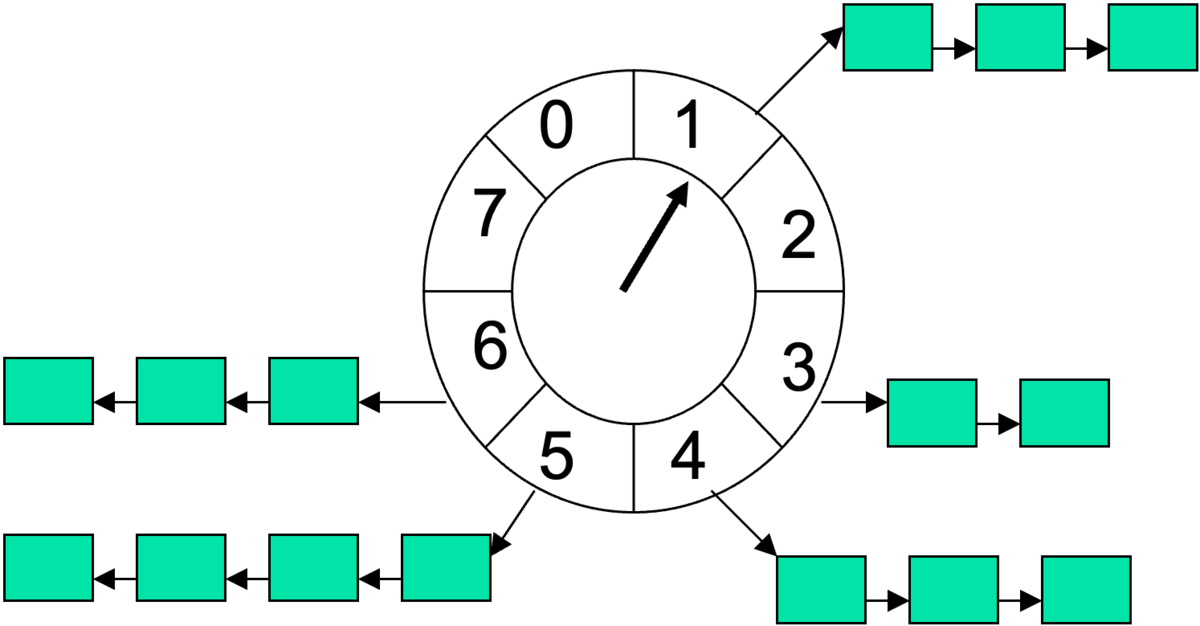
実装 - 現在時刻は[0, MaxInterval - 1]の範囲の円形バッファ内の要素のインデックスで表される - 現在時刻 i からj単位後にタイマーを設定するには ((i+j) mod MaxInterval)番目の要素にタイマーを追加する。
処理の流れ - 毎ティックごとに現在のタイマーポインタをインクリメント & (mod MaxInterval)する - 指している配列要素をチェック - 要素があれば、そこに格納されているすべてのタイマーに対して EXPIRY_PROCESSING を実行
この方式でスケジュール可能なのは現在時刻から MaxInterval タスクです。 そのため 1tick = 1秒 のような設定で1時間後のタスクを設定すると MaxInterval = 3600 とする必要があり、3600要素の配列が必要になってしまいます。
この方式では PER_TICK_BOOKKEEPING も START_TIMER も O(1) で実装可能で今までの方式の上位互換のように見えますが、時間的性能の代償として大量のメモリ量が必要になります。(= 空間的性能が下がる)
メモリ使用量と処理時間をトレードオフにするという性能特性はバケットソートに類似しています。(というよりバケットを用意しているので、そもそもバケットソートしているのとかなり似た戦略になっている)
ハッシュを使う
上記の Timing Wheel の課題はハッシュを使えば以下のように改善できます。
- MaxIntervalまでの全ての要素を確保するのではなくもう少し小さいサイズのテーブルを確保する。
- (タイマー時刻 mod タイマーで持つテーブルのサイズ)で計算されるインデックスに要素を確保する
- 各tickでは無条件に expire させていくのではなく、実際に expire 時刻に達しているかチェックしながら expire させる。
ここで、テーブルの各要素に含まれるListをソートするか、しないか(priority queueにするかしないか)で二種類の亜種がうまれるので以下で解説します。
方式5. - Hashed Timing Wheel (ハッシュテーブル + ソート済みリスト方式)
- 各リストはScheme 2と同様に順序付けられたリストとして管理する
- START_TIMERは要素をソート済みリストの適切な位置に挿入する必要があり遅くなる可能性がある
- ただし、n < TableSizeかつハッシュ関数が均一に分散する場合、平均レイテンシは O(1)となる
方式 6 Hashed Timing Wheel (ハッシュテーブル + 非ソートリスト方式)
- 各リストを順序なしリストとして管理する
- START_TIMERの最悪ケースと平均レイテンシが O(1) に改善
- ただし PER_TICK_BOOKKEEPING の処理時間は(リスト内の全要素をチェックしなければならないので)増加する
方式5,6はどちらもタイトルにある Hashed Timing Wheel となります。 これで START_TIMER, PER_TICK_BOOKKEEPING が O(1) (もちろん STOP_TIMER もO(1))で、空間効率(メモリ量)も良いタイマーアルゴリズムが得られました!
論文ではHierarchical Timing Wheelについても触れられていますのでこちらについても見ていきましょう。
方式7. Hierarchical Timing Wheel
方式4のTiming Wheelでは 0~MaxInterval個の要素が必要である点がネックでした。方式6のHashed Timing WheelではそれをHashテーブルを使って解決していました。 方式7では方式4の問題を階層構造を使って解決します。
まず、階層構造を活用すれば(例えば)32ビットの範囲のタイマー値を表現するのに 232個の要素を持つ配列は不要です。
例えば、100日分のタイマーを格納するのには以下の4つの配列を使えば十分です。 - 日単位の100要素配列 - 時間単位の24要素配列 - 分単位の60要素配列 - 秒単位の60要素配列
もし階層構造を使わない場合は 100 * 24 * 60 * 60 = 864万要素の配列が必要ですが、上記実装であれば100 + 24 + 60 + 60 = 244個の要素ですみます。
このような階層構造を持たせたデータ構造を Hierarchical Timing Wheelといいます。
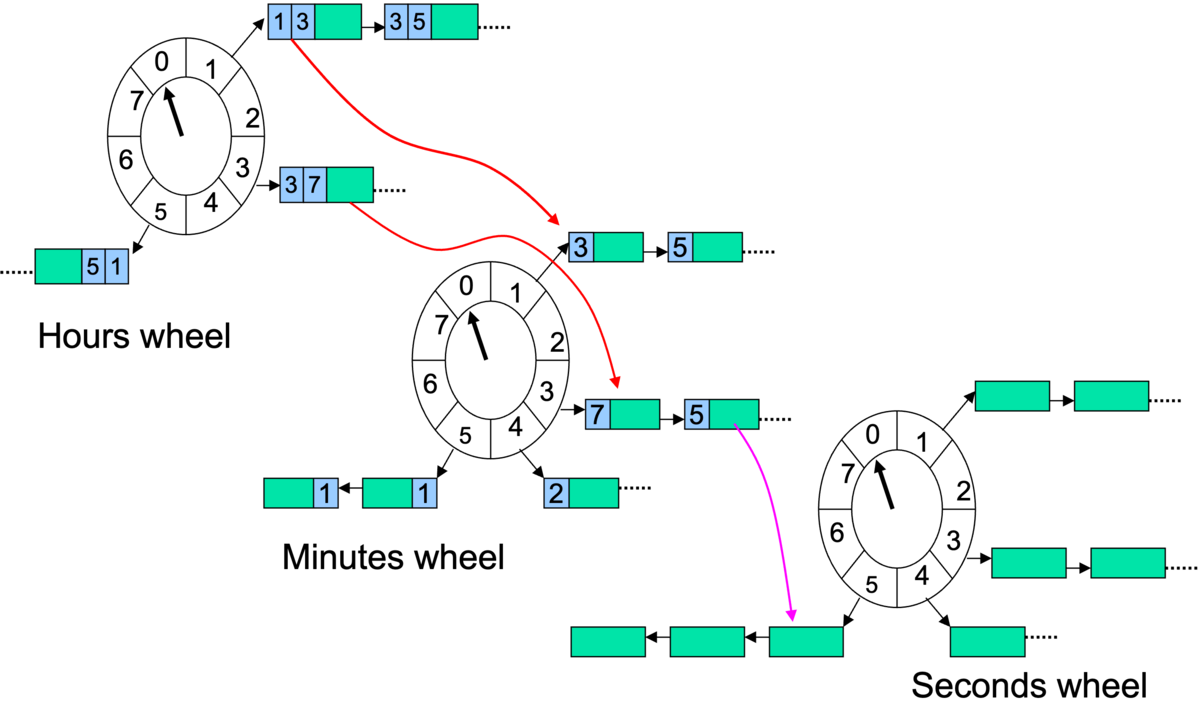
動作
- 10:24:30 秒であれば以下のような表現になる
- HOUR ARRAY POINTER = 10要素目を指す
- MINUTE ARRAY POINTER = 24要素目を指す
- SECOND ARRAY POINTER = 30要素目を指す
- ここで 11:15:15 のタイマーをセットすると以下の動作になる
- HOUR ARRAY[11] に (15min, 15sec) というレコードを挿入する
- 時間が進みHOUR ARRAY POINTETRが10要素目から11要素目に更新されると、HOUR ARRAY[11]内のリストが走査される
- これにより MINUTE ARRAY[15] に (15sec) というレコードが挿入される
- 時間が進みMINUTE ARRAY POINTETRが14要素目から15要素目に更新されると、MINUTE ARRAY[15]内のリストが走査される
- これにより SECOND ARRAY[15] にレコードが挿入される(中身はexpiry_action)
- 時間が進みSECOND ARRAY POINTETRが14要素目から15要素目に更新されると、SECOND ARRAY[15]内のリストが走査される。
- 上記リスト内の EXPIRY_PROCESSING がそれぞれ実行される
パフォーマンス特性
- START_TIMER: insertを階層分だけ行うので配列数mに対してO(m)かかる。(ただしmの推奨値が 2 <= m <5 程度なのであまり気にしなくても良い)
- STOP_TIMER: 二重リンクリストを使用すれば O(1) で実行可能
- PER_TICK_BOOKKEEPING: Scheme 6と同様に十分大きな配列サイズで平均 O(1) のレイテンシーとなる
- ただしHierarchical TIming Wheelは大きなタイマー間隔(T)と小さなメモリ量(M)の場合、Hashed Wheel Bucket よりも良好な平均コストを実現する(次で比較)
平均処理時間の比較
- Scheme 6の平均コストでは1タイマーあたりの総作業量は以下のようになります
- c(6) ∗T/M
- c(6): インデックス処理等の要素ごとの固定コスト
- T: 平均タイマー間隔
- M: 配列要素の総数
- ※ Hash的には該当するが expire のタイニングではない場合のオーバーヘッドが計算されている
- Scheme 7の平均コスト
- 1タイマーあたりの総作業量:
- c(7)∗m
- c(7): 次のリストへの移行コストと移行処理のコスト
- m: 階層の数(通常2〜5)
- ※ 階層移動の数だけオーバーヘッドがある
Tに対してMを大きく取ればHashed Timing Wheelのコストは無視できそうですが、その分メモリ効率は悪くなるといったことのようです。論文だとDAYみたいな階層もあったのでそれなりに長めの時間間隔を想定しているのかもしれません。たしかに数日先のスケジュールに対して限定されたテーブルサイズの Hashed Timing Wheel を適用すると何周分も固定コストを払うことになるので、そういったスケジュールが多い場合は効率が悪そうです。(M = テーブルサイズを何周分も固定コストを払う必要はありませんが、その場合は空間効率が悪くなります。)
論文のまとめ
ここまで論文を通して Hashed Timing Wheel (= HashedWheelTimerの内部構造)と、(ついでに)Hierarchical Timing Wheel について見てきました。 続いて実装していきたいところですが、良い記事があったのでそちらを紹介します。
Hashed Wheel TImer の実装例
Hashed Wheel Timers - DEV Community
かなりシンプルで見通しやすいと思いましたので目を通しておくとよいと思います。
実用例
さて、ここまで仕組みの話をしていましたが実際にどういった OSS で使われているのか見ていきましょう。(全部の実装を確認したわけじゃないのでクラス名やコメントがそうなっているだけで実態は違うとかあったらごめんなさい)
- Netty
- そのまま HashedWheelTimer というクラスがあります
- Akka
- LightArrayRevolverScheduler が Netty ライクな HashedWheelTimer と記載があります。
- LightArrayRevolverScheduler は reference.conf で指定されているデフォルトのスケジューラです。
- akka/akka-actor/src/main/resources/reference.conf at 249efae2a2974e75603bb7e9244f9f128e0a291d · akka/akka · GitHub
- akka-http のHTTP timeoutがこれで処理されているはずですが、ややわかりにくいので次のブログで説明しようと思います。
- Finagle
- 基本的には Netty を使っているようです
- finagle/finagle-netty4/src/main/scala/com/twitter/finagle/netty4/Netty4HashedWheelTimer.scala at 53d6894b9fd80bda75c4c58313cfd86ad25eba9e · twitter/finagle · GitHub
- timer というクラスで timeout や schedule などを行うのですが ServiceLoader という仕組みを使っています。(META-INF 内にサービスに該当する実装クラスを書くとそれを読み込んでくれる仕組み)
- Kafka
- こちらは Hierarchical Timing Wheel を使っています。
- kafka/server-common/src/main/java/org/apache/kafka/server/util/timer/TimingWheel.java at cd5a7ee6b2a800302b34332c3d7c93fca309f116 · apache/kafka · GitHub
理解しておくとどういうときに役に立つのか
Scheduler について知らなくても Timeout はいくらでも設定できるわけですが、例えばライブラリやミドルウェアの不思議な挙動に遭遇した時に知っておくと課題解決スピードが上がりそうです。
例えば下記資料ではLettuceで発生したコネクションの問題の調査で HashedWheelTimer を含めた範囲で調査が行われているようです。
※ 軽く検索してみると Nettyの実装を利用しているようです。 lettuce/src/main/java/io/lettuce/core/resource/DefaultClientResources.java at b396f621cbc6e88cd50e9e117addcaecf040abca · redis/lettuce · GitHub
(自分も Kafka のやや面倒な問題の調査をしているときにどこで処理が止まっているのか調査したときにスケジューラー周りの実装を読んだことがあるので、そういったトラブルシュートの際には知っていて損はなさそうです。)
ちなみに
おなじ Timeout でも CompletableFuture は ScheduledThreadPoolExecutor を採用しており、これは DelayedWorkQueue というヒープベースのプライオリティキューを採用しています。
- https://github.com/openjdk/jdk/blob/edbd76c62482df31cf539672c6950f00121bcbf3/src/java.base/share/classes/java/util/concurrent/ScheduledThreadPoolExecutor.java#L883
- https://github.com/openjdk/jdk/blob/bd3c0be36d929fab5e5ca0158d53e50b2d206707/src/java.base/share/classes/java/util/concurrent/ScheduledThreadPoolExecutor.java#L329
探した感じ Spring の HttpClient の timeout に使われていました(ワークアラウンドのようですが) server 側では何を使ってるのか調べたいような気がしましたが長くなるので今回は辞めておきました
終わりに
最近は海外記事でも論文でも chatGPT なりがまとめてくれるので必要があればすぐ勉強できますね。そういう状況でわざわざ日本語で記事を書く必要があるのかというのはありますが、まあいざ解説しようとすると色々調べたりして勉強になったので良しとしました。
株式会社FOLIOでは、このような記事を最後まで読んでくれる もの好き 優しい人を大募集中です。 バックエンドエンジニア以外にも大々募集中ですのでまずは下記フォームでカジュアル面談にご応募ください 🙏
※ 入力は名前とメアドだけで大丈夫です 🙆♀️